
Introduction
Over the course of this Spring, I have sought to develop my skills and familiarity with the various translation technologies, both established and developing, that have a large impact on the language industry. To that end, I, along with some of my colleagues, simulated a long-term projects aimed at creating and training an NMT (Neural Machine Translation) Engine. If you want the gist of it all, feel free to skip to the Lessons Learned video below. Otherwise, keep reading to get a more a comprehensive look at the project.
If you want to take a look at the other project I simulated over this Spring, please check out the TMS Project.
NMT Engine Training
The Background
Neural Machine Translation Engines differ from normal Machine Translations Engines in that they rely on neural networks and deep learning techniques supported by large volumes of bilingual text, rather than pre-defined rules and phrase-based translation. This allows them to be more adaptable and account for a variety of specialized language and styles. They function using the same essential technology as LLMs (Large Language Models) such as ChatGPT to translate, but where LLMs draw on a seemingly infinite amount of disperse sources across the internet to ‘learn’ how to translate, NMT engines rely on whatever content they are given. In this way, language teams can train an NMT to translate a specific type of content, and create a specialized engine for that content only. For example, if you wanted to train an NMT engine to translate car manuals, you would feed it bilingual text data from several already translated manuals, and the engine would ‘learn’ from them how to translate car manuals in that style. Essentially, NMT serves as a happy medium in between the power and adaptability of LLMs and the specificity and customization of traditional MT engines.
The Goal of this Project
For this project we wanted to try our hands at training an NMT Engine to translate Japanese RPG dialogue into English. In order to provide the engine with appropriate data, we selected a series of famous Japanese RPGs, primarily Final Fantasy titles, and used the bilingual translations available. After training, we tested our engine by feeding it monolingual Japanese text from Final Fantasy IV, and in order to evaluate the quality of the engine’s output, we devised a series of holisitc and analytic quality metrics. The ultimate goal was to test if the NMT Engine training process would ultimately save time and costs on traditional translation methods. To learn more about the goals of the project, its purpose, the data, the timeline, the costs, the quality metrics or any other such details, please feel free to read through the proposal below.
Training an Engine
Although it might sound overly technical and complicated, the NMT Engine training process is a relatively simple one.
- Choose an NMT engine hosting service
- Popular options are Systran Model Studio and Microsoft Azure AI Custom Translator
- Our team chose Microsoft
- Popular options are Systran Model Studio and Microsoft Azure AI Custom Translator
- Gather a large amount of data and clean it
- The minimum number of bilingual sentences required for Microsoft was 10,000
- Categorize your data into training, tuning, and testing data sets
- Learn more about Data Set Types
- Run the training
- This could take several hours
- Perform quality analysis
- At minimum, note the BLEU Score
- Change the data and run training again
- You can switch up the training and tuning data, add more data, or clean the data further
- Compare new training quality data with previous
- Hopefully the quality is better and you have a higher BLEU score
- Repeat 3-7 until quality goals are achieved
How did our project go?
Please view the video below to watch the team’s reflections on the project. Otherwise, you can read through a summary below it.
To put it simply, our project indicated that training an NMT engine based on our data and parameters would not be as cost or time efficient as traditional translation processes. Simply put, the translations of the testing data did not score well on our analytic or holistic evaluation scales, and our BLEU scores indicated that over 6 rounds of training, our NMT Engine was not improving greatly, with it starting out in the first round at 17.79 and ending in the sixth round at 18.39.
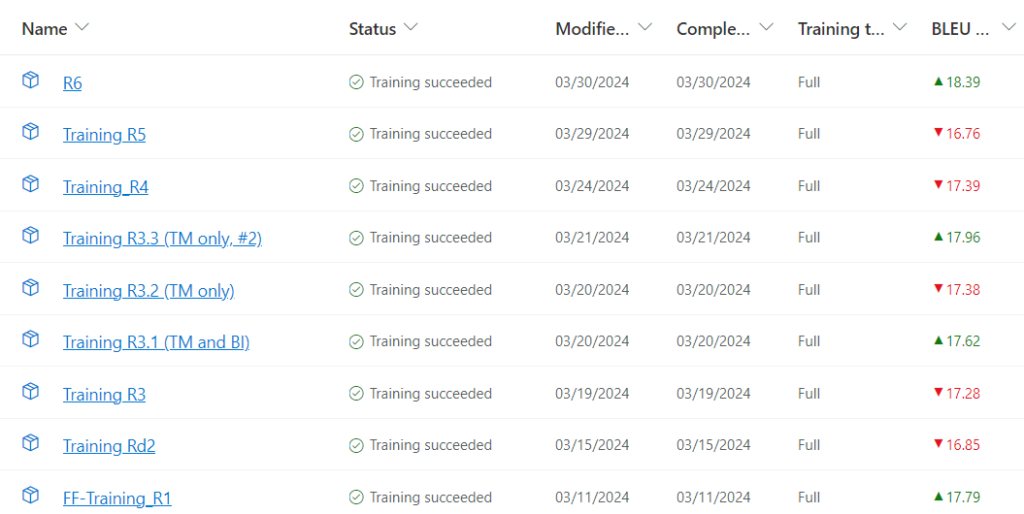
Nevertheless after deliberation, our team and I indicated that the most likely cause of the underwhelming scores was our data. Being that we were working outside of a company and had to source and extract our bilingual texts from various online sources, it was a very time consuming process to find data. This meant that our engine trained on the minimum amount of data required, rather than a surplus of data. The texts also came from different sources and were formatted differently, which could have confused the engine during training. Despite the lack of obvious success, we were still able to produce an engine that did a decent job of translating Japanese RPG texts to English, and while the project struggled because of our free, internet-sourced data, I am confident that given official scripts and translations, the Engine would perform much better.
Quick NMT Concept Guide
Data Cleaning
Raw translation data is very rarely clean and devoid of imperfections that could confuse an NMT during training. For this reason, it is a good idea to check the translation for elements such as tags, comments, overly specific and non-repeatable translations, exceptionally long or short translations, etc. To do this on scale, a tool like Olifant is useful.
Data Types
| Training | Tuning | Testing |
|---|---|---|
| Bilingual | Bilingual | Monolingual |
| Most of the data is training data. This is used by the NMT engine to recognize context and patterns and build a general understanding of how to translate from one language to another. | A smaller amount of the data. This is generally data that has been cleaned more and serves as a “best sample” to help the engine make choices and refine its translation decisions while parsing through the Training data. | Used to show a sample translation done by the newly trained engine. Often, this is used to for quality analysis. |
BLEU Score
The Bilingual Evaluation Understudy Score is used to test for how close a Machine Translate Engine has translated a text as compared to an approved human translation of the same text. In general, a higher BLEU Score indicates that the MT is closer to the human translation. However, it must be said that a BLEU score is NOT a measure of quality, only a measure of similarity. For a BLEU Score to be useful, the human translation for comparison should be high quality. In the context of NMT training, a BLEU score is given at the end of each training round to show how close its translation of the testing data was to a provided translation of the testing data. If the score increases after a round of training, it generally indicates that whatever change was made caused the NMT Engine to produce a translation closer to the human translation.